ASCII (Amerikaanse standaardcode voor informatie-uitwisseling) - standaardtekstcodering voor het Latijnse alfabet
Volgens de International Telecommunication Union, in2016, het internet met een zekere regelmaat genoten van drie en een half miljard mensen. De meesten van hen denken zelfs niet dat berichten die ze via pc's of mobiele gadgets verzenden, evenals teksten die op allerlei monitors worden weergegeven, eigenlijk combinaties van 0 en 1 zijn. Een dergelijke weergave van informatie wordt codering genoemd. Het biedt en vergemakkelijkt de implementatie van de opslag, verwerking en verzending ervan aanzienlijk. In 1963 werd de Amerikaanse codering van ASCII ontwikkeld, het onderwerp van dit artikel.

Presentatie van informatie op de computer
Vanuit het oogpunt van elke elektronische computerDe machinetekst bestaat uit een reeks afzonderlijke tekens. Ze omvatten niet alleen letters, inclusief hoofdletters, maar ook leestekens, cijfers. Bovendien worden de speciale symbolen "=", "&", "(" en spaties gebruikt.
De set tekens waaruit de tekst bestaat,wordt het alfabet genoemd en hun nummer is de macht (aangeduid als N). Om dit te bepalen, gebruikt u de uitdrukking N = 2 ^ b, waarbij b het aantal bits is of het informatiegewicht van een bepaald symbool.
Het is bewezen dat een alfabet met een capaciteit van 256 tekens u in staat stelt alle noodzakelijke symbolen weer te geven.
Omdat 256 de 8e macht van twee is, is het gewicht van elk symbool 8 bits.
Een eenheid van 8 bits wordt een 1 byte genoemd, dus het is gebruikelijk om te zeggen dat de binaire code van elk teken in de tekst die op de computer is opgeslagen, één byte geheugen in beslag neemt.

Hoe codering wordt uitgevoerd
Alle teksten worden in het geheugen van een persoon ingevoerdcomputer door middel van toetsen van het toetsenbord waarop cijfers, letters, leestekens en andere symbolen zijn geschreven. In het geheugen worden ze verzonden in binaire code, dat wil zeggen dat elk teken overeenkomt met de gebruikelijke menselijke decimale code, van 0 tot 255, wat overeenkomt met een binaire code - van 00000000 tot 11111111.
Byte-byte tekencodering maakt het mogelijkde processor die de verwerking van de tekst uitvoert, heeft toegang tot elk symbool afzonderlijk. Tegelijkertijd zijn 256 tekens voldoende om elke tekeninformatie weer te geven.

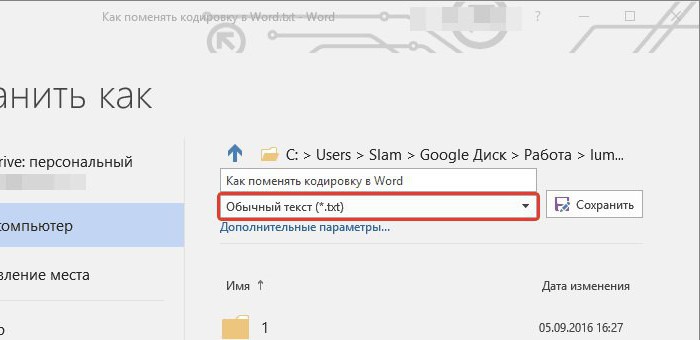
Tekencodering ASCII
Deze Engelse afkorting staat voor Amerikaanse standaardcode voor informatie-uitwisseling.
Aan het begin van de automatisering werd het duidelijk datje kunt een breed scala aan manieren bedenken om informatie te coderen. Voor het overbrengen van informatie van de ene naar de andere computer was het echter nodig om één enkele standaard te ontwikkelen. Dus in 1963 in de VS was er een ASCII-coderingstabel. Hierin wordt aan elk symbool van het computeralfabet het serienummer toegewezen in de binaire weergave. Aanvankelijk werd de ASCII-codering alleen in de Verenigde Staten gebruikt en werd toen de internationale standaard voor de pc.
Inhoud van de tabel
De ASCII-codes zijn verdeeld in twee delen. De internationale standaard is slechts de eerste helft van deze tabel. Het bevat symbolen met ordinale getallen van 0 (gecodeerd als 00000000) tot 127 (code 01111111).
Volgnummer N | ASCII-tekstcodering | symbool |
0 - 31 | 0000 0000 - 0001 1111 | Symbolen met N van 0 tot 31 worden managers genoemd. Hun functie is om het proces van het uitvoeren van tekst naar een monitor of een afdrukapparaat te "geleiden", een geluidssignaal te geven, enz. |
32 - 127 | 0010 0000 - 0111 1111 | Symbolen met N van 32 tot 127 (het standaardgedeeltetabellen) - hoofdletters en kleine letters van het Latijnse alfabet, 10 cijfers, leestekens, evenals verschillende haken, commerciële en andere symbolen. Het symbool 32 geeft een spatie aan. |
128 - 255 | 1000 0000 - 1111 1111 | Symbolen met N van 128 tot 255 (alternatief deeltabellen of codetabel) kunnen verschillende varianten hebben, die elk hun eigen nummer hebben. De codepagina wordt gebruikt om de nationale alfabetten te specificeren, die verschillen van het Latijnse alfabet. In het bijzonder is het met zijn hulp dat ASCII is gecodeerd voor Russische karakters. |
In de coderingstabel volgen hoofdletters en kleine letters elkaar in alfabetische volgorde en zijn de nummers in stijgende volgorde. Dit principe is ook bewaard voor het Russische alfabet.
Beheer tekens
De ASCII-coderingstabel is oorspronkelijk gemaaktvoor het ontvangen en verzenden van informatie op een apparaat dat lange tijd niet is gebruikt, zoals een teletype. In dit opzicht zijn de niet-afdrukken, gebruikt als opdrachten voor het besturen van dit apparaat, opgenomen in de tekenset. Vergelijkbare commando's werden gebruikt in dergelijke precomputer messaging-methoden als morsecode, etc.
Het meest voorkomende "teletype" -symbool is NUL (00, "nul"). Het wordt nog steeds gebruikt in de meeste programmeertalen, waarmee het einde van de regel wordt aangeduid.

Waar de ASCII-codering wordt gebruikt
Amerikaanse standaardcode is niet alleen nodigom tekstinformatie in te voeren via het toetsenbord. Het wordt ook gebruikt in afbeeldingen. In het bijzonder, in het ASCII Art Maker-programma, vertegenwoordigen afbeeldingen van verschillende extensies een reeks ASCII-tekensymbolen.
Vergelijkbare producten zijn er in twee soorten: De functie van grafische editors uitvoeren door afbeeldingen in tekst om te zetten en "tekeningen" naar ASCII-afbeeldingen te converteren. Een bekende smiley is bijvoorbeeld een levendig voorbeeld van een coderingssymbool.
ASCII kan ook worden gebruikt bij het maken van een HTML-document. In dit geval kunt u een bepaalde reeks tekens invoeren en wanneer u de pagina bekijkt, verschijnt een symbool op het scherm dat overeenkomt met deze code.
ASCII is ook vereist voor het maken van meertalige sites, aangezien tekens die geen deel uitmaken van een specifieke nationale tabel worden vervangen door ASCII-codes.

Sommige functies
Om tekstinformatie in ASCII-codering te coderen, werden in eerste instantie 7 bits gebruikt (één was leeg), maar vandaag werkt het als een 8-bits exemplaar.
De letters in de kolommen aan de boven- en onderkant verschillen alleen van elkaar door een enkel bit. Dit vermindert de complexiteit van verificatie aanzienlijk.
ASCII gebruiken in Microsoft Office
Indien nodig dit type tekstcoderinginformatie kan worden gebruikt in de teksteditors van Microsoft, zoals Kladblok en Office Word. Wanneer u echter typt, is het in dit geval niet mogelijk om sommige functies te gebruiken. U kunt bijvoorbeeld geen vetgedrukte selectie maken, omdat de ASCII-codering alleen de betekenis van de informatie behoudt en het algemene uiterlijk en de vorm negeert.
normalisering
ISO heeft de ISO 8859-normen overgenomen. Deze groep definieert acht-bit coderingen voor verschillende taalgroepen. ISO 8859-1 is met name Extended ASCII, een tabel voor de Verenigde Staten en de West-Europese landen. En ISO 8859-5 is een tabel die wordt gebruikt voor Cyrillisch, inclusief Russisch.
Om een aantal historische redenen werd de ISO 8859-5-standaard niet erg lang gebruikt.
Voor de Russische taal op het moment, wordt codering echt gebruikt:
- CP866 (Code Pagina 866) of DOS, wat vaak een alternatieve codering GOST wordt genoemd. Het werd actief gebruikt tot het midden van de jaren 90 van de vorige eeuw. Op dit moment bijna niet gebruikt.
- KOI-8. Codering is ontwikkeld in de jaren 1970-80, enDit is de standaard voor e-mailberichten in RuNet. Het wordt veel gebruikt in het besturingssysteem van de Unix-familie, inclusief Linux. De "Russische" versie van KOI-8 heet KOI-8R. Daarnaast zijn er versies voor andere Cyrillische talen, bijvoorbeeld Oekraïens.
- Code Pagina 1251 (CP 1251, Windows - 1251). Ontwikkeld door Microsoft Corporation om ondersteuning te bieden voor de Russische taal in een Windows-omgeving.
Het belangrijkste voordeel van de eerste standaard CP866was het behoud van pseudo-grafische symbolen op dezelfde posities als in Extended ASCII. Hierdoor konden ongewijzigde tekstprogramma's, buitenlandse productie, zoals de beroemde Norton Commander, worden uitgevoerd. Op dit moment wordt CP866 gebruikt voor programma's die zijn ontwikkeld onder Windows en die werken in de modus Volledig scherm of in tekstvensters, waaronder FAR Manager.
Computerteksten, geschreven in de CP866-codering, zijn recentelijk zeldzaam geweest, maar het wordt gebruikt voor Russische bestandsnamen in "Vindous".
"Unicode"
Op dit moment, de meest voorkomendeontving deze specifieke codering. Unicode-codes zijn onderverdeeld in regio's. De eerste (van U + 0000 tot U + 007F) bevat de tekens van de ASCII-set met codes. Volg vervolgens de gebieden met tekens van verschillende nationale scripts, evenals leestekens en technische symbolen. Daarnaast is een deel van de Unicode-codes gereserveerd voor het geval er in de toekomst nieuwe symbolen moeten worden opgenomen.

Nu weet je dat in de ASCII-codering, elkhet symbool wordt weergegeven als een combinatie van 8 nullen en enen. Voor niet-specialisten kan deze informatie onnodig en oninteressant lijken, maar wil je niet weten wat er in het 'brein' van je pc gebeurt ?!
</ p>